这里记录人工智能的大事件,内容可能不完整,将不定期补充和更新:
- 1943年:Warren S. McCulloch 和 Walter Pitts 提出了人工神经元模型。论文链接:A Logical Calculus of the Ideas Immanent in Nervous Activity。
- 1950年:A. M. Turing 提出了著名的图灵测试。论文链接:Computing Machinery and Intelligence。
- 1956年:达特茅斯会议 Dartmouth workshop。会议上对人工智能的概念进行了明确定义,并提出了一系列解决复杂问题的方法和算法。尽管达特茅斯会议并未立即引起广泛的关注,但它标志着人工智能作为一个独立领域的开始。
- 1957年:Rosenblatt, F. 提出了第一个可以学习的神经网络模型,称为感知器(Perceptron)。论文链接: The perceptron: A probabilistic model for information storage and organization in the brain。
- 1982年:J. J. Hopfield 提出 Hopfield 网络。论文链接:Neural networks and physical systems with emergent collective computational abilities。
- 1985年:David H. Ackley,Geoffrey E. Hinton 和 Terrence J. Sejnowski 提出玻尔兹曼机(boltzmann machine)。论文链接:A learning algorithm for boltzmann machines。
- 1986年:David E. Rumelhart,Geoffrey E. Hinton 和 Ronald J. Williams 给出反向传播算法。论文链接:Learning representations by back-propagating errors。
- 1997年:IBM的深蓝计算机击败国际象棋世界冠军加里·卡斯帕罗夫。论文链接:Deep Blue。
- 1998年:Lecun等人提出 LeNet-5,用于手写数字识别任务,是最早的卷积神经网络之一,为许多后续的深度学习架构奠定了基础。论文链接:Gradient-based learning applied to document recognition。
- 2009年:李飞飞教授发布 ImageNet 项目。这个项目对于推动深度学习、卷积神经网络等技术的发展起到了重要作用,成为了许多机器学习研究的基准数据集之一。论文链接:ImageNet: A large-scale hierarchical image database。
- 2012年:Alex Krizhevsky、Ilya Sutskever和 Geoffrey Hinton 提出 AlexNet 卷积神经网络。该模型利用深度卷积神经网络取得了 ImageNet 图像分类竞赛(ILSVRC)的胜利,标志着深度学习在计算机视觉领域的崛起。论文链接:ImageNet classification with deep convolutional neural networks。
- 2014年:Goodfellow 等人提出生成对抗网络(GAN),使得人工智能可以生成逼真的图像、视频和音频等内容。论文链接:Generative Adversarial Networks。
- 2015年:何恺明等人提出 ResNet(Residual Neural Network)模型,通过引入残差学习块解决了深度神经网络训练中的梯度消失问题,成为了图像分类任务中的重要模型。论文链接:Deep Residual Learning for Image Recognition。
- 2016年:DeepMind 的 AlphaGo 击败李世石和柯洁,这标志着人工智能在复杂游戏中的突破。论文链接:Mastering the game of Go with deep neural networks and tree search。
- 2017年:DeepMind 的 AlphaGo Zero 和 AlphaZero 通过自我学习在围棋、国际象棋和将棋领域击败了先前的AlphaGo版本,显示了强化学习在人工智能中的潜力。AlphaGo Zero 论文链接:Mastering the game of Go without human knowledge。AlphaZero 论文链接:A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play。
- 2017年: Google 发布 Transformer 模型。这是一种革命性的自注意力机制模型,用于处理序列到序列的自然语言处理任务。论文链接:Attention Is All You Need。
- 2018年:Google 发布 BERT 模型。这是一种预训练的自然语言处理模型,大大提升了自然语言理解的能力。论文链接:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding。
- 2018年:OpenAI发布 GPT-1 模型。论文链接:Improving Language Understanding by Generative Pre-Training。
- 2019年:OpenAI 发布 GPT-2 模型。论文链接:Language Models are Unsupervised Multitask Learners。
- 2020年:OpenAI 发布 GPT-3 模型。论文链接:Language Models are Few-Shot Learners。
- 2022年:OpenAI 发布 ChatGPT。它在自然语言处理领域表现出色,被认为是人工智能发展历史上的重要里程碑之一。
- 2023年:阿里巴巴开源 Qwen 一系列大语言模型,并逐渐在开源大模型市场中占据一席之地。论文链接:Qwen Technical Report。
- 2024年:John J. Hopfield 和 Geoffrey E. Hinton 获得2024年诺贝尔物理学奖。新闻链接:https://www.nobelprize.org/prizes/physics/2024/press-release/。
- 2025年:DeepSeek 开源推理模型 DeepSeek-R1,该模型通过大规模强化学习技术显著提升推理能力,它具有性能强、成本低等优点。论文链接:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning。
- ……
附神经网络的进化图:
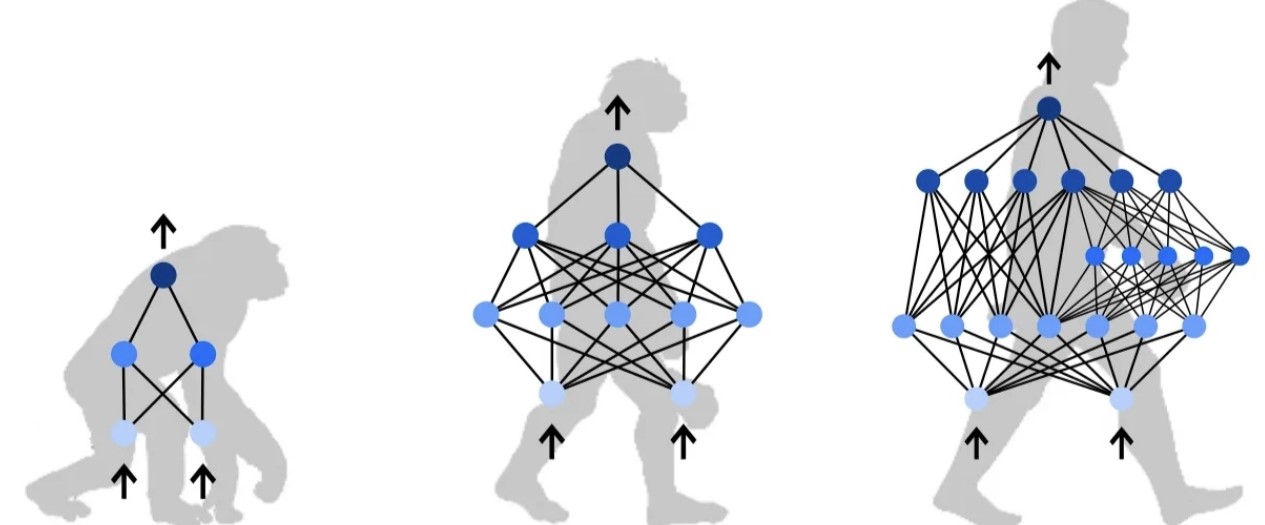
其他参考资料:
【说明:本站主要是个人笔记和代码的分享,内容可能会不定期修改。目前文章支持直接转载,引用或转载请注明出处:https://www.guanjihuan.com 。本站采用知识共享署名许可协议 CC BY】